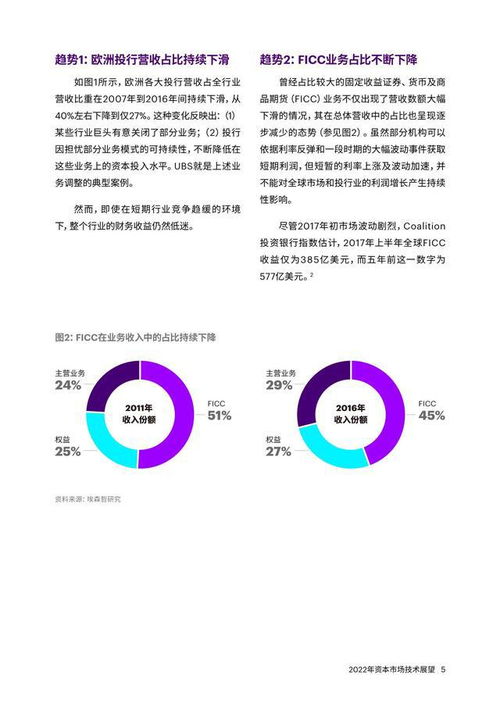
基于Puppeteer、RabbitMQ与Node.js的PDF批量加工服务架构设计与落地实践
背景与需求
在数字内容制作服务领域,PDF文档的批量生成与加工是一项常见且需求频繁的任务。无论是电商平台的商品详情页导出、企业内部的报表自动化生成,还是在线教育机构的学习资料打包,都需要高效、稳定且可扩展的PDF处理服务。传统的手动或单机处理方式不仅效率低下,且难以应对高并发、大规模的处理需求。为此,我们设计并落地了一套基于Puppeteer、RabbitMQ与Node.js的分布式PDF批量加工服务架构。
技术选型与核心组件
- Node.js:作为主要运行时环境,其非阻塞I/O和事件驱动特性非常适合处理高并发的I/O密集型任务,如PDF生成中的网络请求、文件读写等。
- Puppeteer:一个由Google Chrome团队维护的Node库,提供高级API通过DevTools协议控制Headless Chrome。它是本架构的核心,负责将HTML内容(包括复杂CSS、JavaScript渲染结果)精准地转换为PDF文档,支持页眉页脚、水印、分页等高级功能。
- RabbitMQ:作为消息代理(Message Broker),实现任务的异步处理与解耦。它负责接收PDF生成任务,并将其可靠地分发给后端的多个Worker进行处理,保障任务不丢失,并实现负载均衡。
系统架构设计
整个系统采用“生产者-消费者”模型,分为以下几个核心模块:
1. 任务接收与调度层(API Gateway/Producer)
- 提供RESTful API接口,接收外部系统提交的PDF生成请求。请求中通常包含HTML内容、PDF配置参数(如尺寸、边距)等。
- 对请求进行基础验证与格式化后,将任务信息封装为消息,发送至RabbitMQ的指定任务队列。每个任务分配唯一ID,便于后续状态追踪。
- 此层为无状态服务,可水平扩展以应对高并发请求。
2. 消息队列层(RabbitMQ)
- 使用工作队列(Work Queue)模式。创建一个或多个持久化的队列,用于存储待处理的PDF任务消息,确保服务器重启后任务不丢失。
- 可以配置多个队列以实现优先级处理(如VIP用户任务进入高优先级队列)。
- 消息确认(Ack)机制确保任务被Worker成功处理后才会从队列中移除,防止任务丢失。
3. 任务处理层(Worker/Consumer)
- 由多个独立的Node.js进程(Worker)组成,每个进程都是一个消费者,从RabbitMQ队列中拉取任务。
* Worker核心逻辑:
a. 从消息中解析出HTML内容和配置。
b. 启动(或复用)一个Puppeteer实例,打开一个空白页。
c. 将HTML内容注入页面,等待必要的资源加载和脚本执行(可使用page.waitForNetworkIdle或page.waitForSelector)。
d. 调用page.pdf()方法,根据配置生成PDF Buffer。
e. 将生成的PDF上传至持久化存储(如AWS S3、阿里云OSS或服务器本地磁盘),并获取文件访问URL。
f. 将任务ID、状态(成功/失败)、PDF URL或错误信息更新至数据库(如MongoDB、Redis)。
g. 向RabbitMQ发送任务完成确认(Ack)。
- Worker可以水平扩展,通过增加实例数量来提升整体处理能力。
4. 状态查询与结果返回层
- 提供独立的API,供客户端根据任务ID轮询或通过WebHook回调通知,获取任务处理状态(处理中、成功、失败)及结果(PDF文件URL)。
- 状态信息通常存储在Redis或数据库中,保证查询效率。
5. 存储与缓存层
- 对象存储:用于保存最终生成的PDF文件,推荐使用云服务(S3、OSS)以获得高可靠性和可扩展性。
- 数据库/缓存:记录任务元数据、状态及结果索引,用于状态查询和系统监控。
关键优化与落地实践
- Puppeteer实例管理:频繁启动关闭浏览器实例开销巨大。采用浏览器实例池进行复用,每个Worker维护一个可重用的实例池,显著提升处理速度并降低资源消耗。
- 错误处理与重试:在Worker中实现健壮的错误捕获。对于网络波动等临时性错误,将任务重新放回队列(Nack with requeue)进行重试;对于不可恢复错误(如HTML格式错误),则标记任务失败并记录日志。
- 资源隔离与限制:每个Puppeteer任务消耗一定内存和CPU。通过控制Worker并发处理任务数、限制单个Puppeteer页面的内存使用,防止单个任务拖垮整个服务。可使用Docker进行容器化部署,便于资源限制和管理。
- 监控与告警:对RabbitMQ队列长度(堆积情况)、Worker处理速度、任务失败率等关键指标进行监控。队列积压过多时触发告警,便于及时扩容Worker。
- 部署与伸缩:将API层和Worker层分别容器化。在Kubernetes或云服务器集群上部署,并配置HPA(Horizontal Pod Autoscaling)或基于队列长度的自动伸缩策略,实现根据负载动态调整Worker数量。
##
本架构结合了Puppeteer强大的渲染能力、RabbitMQ可靠的消息异步处理能力以及Node.js的高效I/O模型,构建了一个高性能、高可靠、可水平扩展的PDF批量加工服务。它成功地将同步、耗时的PDF生成过程转化为异步、分布式的流水线作业,有效支撑了数字内容制作服务中大规模、高并发的PDF导出需求,提升了系统整体的吞吐量与稳定性。该架构模式也可被借鉴于其他类似的批量文档处理、图片生成等场景。
如若转载,请注明出处:http://www.dqxbw.com/product/11.html
更新时间:2026-06-19 19:37:02